Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
This is a short article that might actually provide a very useful tip. When testing AI on the basis of win/lose counts it is hard to intuitively assess the significance of test results on-the-fly. In a two player contest the binomial distribution is very helpful in that it allows the significance of a result to be assessed. However not all test situations are so amenable to such analysis.
Here we detail a simple useful trick that avoids this problem.
Background
From earlier articles we have detailed tools for assessing significance. In particular Statistical Minefields with Version Testing offers the BINOM.EXE programs to reverse engineer the Binomial distribution to assess significance. The same article shows further issues with round robin tournaments with multiple opponents that cannot be used with the Binomial distribution. In such situations, even if you had such a suitable stats program, it still leaves you with the following issue:
You have a testrig running an 8-player round robin tournament, but are the existing running results significant or not? If you had a stats program at hand you might copy the results across and get an answer. This may return "not significant" or "fairly significant", at which point you are left with the decision to perhaps leave the test running longer and then re-test later.
This is annoying as you might test now and it offers a reasonable significance, but if you test again later the significance may even have been reduced, as the outlier winning version gets pegged back.
This consumes time that I'm sure you feel could be better expended elsewhere. It's a distraction!
Solution
Our operated solution to this problem is simple, and made easier using our 32-core Threadripper. We run the same test on multiple cores and simply observe the results from time to time. See the picture below. Here we have the same tournament running on 6-cores. What this allows is "at a glance" to assess that there is no significant result yet as level 27 is winning 3 times and level 31 winning 3 times as well. If we had run just the second trial shown we might well have imagined that level 27 looks promising, so would wheel out the stats program and test the numbers. This would clearly be a waste of time.
By running multiple sessions in parallel it exposes the statistical variability that is the product of a small test sample. In this case it is very clear that we are nowhere near a result, which may even ultimately be heading for a 4-way draw.
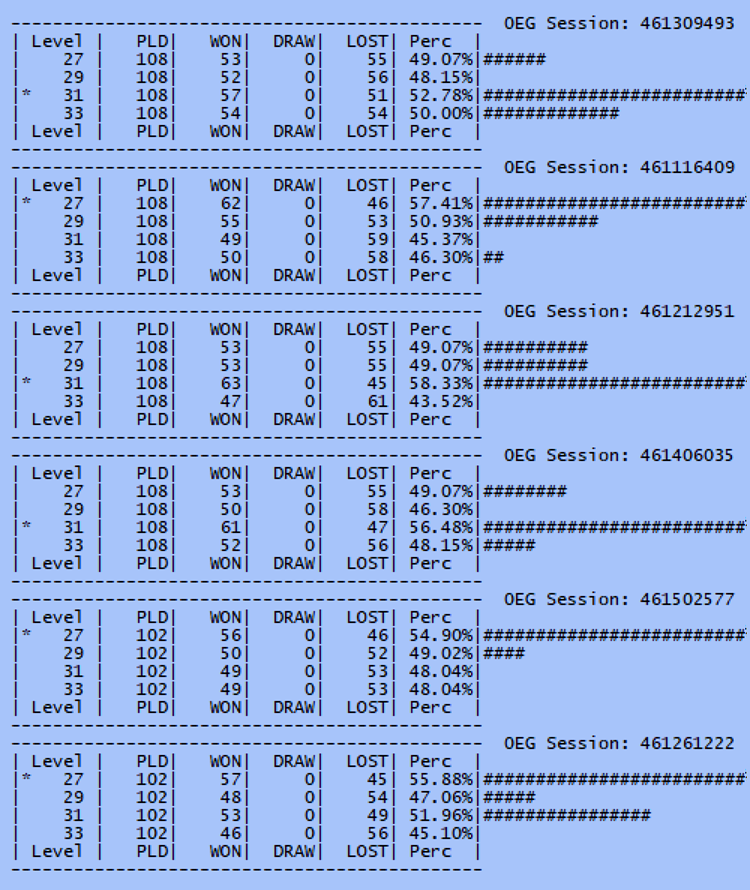
Instead the tester can glance up and immediately see that nothing is happening here after just a couple of seconds and instead return to some other work. Not only is the tester now aware that there is no significant result here but that also they will have some idea of how long they need to wait. If these had already been running for 2 hours then clearly there is little point returning for another 4 hours as these results are a long way off concluding.
There are other benefits as well. If the test is reaching the point that significance is looking likely (in this case perhaps level 27 is ahead in 4 or 5 sessions) then the tester could start up extra tests of level 27 against some other opponent on the basis that it is likely that 27 will prevail. This saves time as the additional tests are started early. If instead 27 later flunks then these added tests can be abandoned at no real cost as there was no other information that would have allowed any other speculative test to be run instead.
Conclusion
This is a significant time saver but it does not propel the tester to publish statistically dubious results just on the basis of intuition. These are just advance signposts, rather like "heavy traffic ahead", so that the tester can make good decisions in advance. The tester can assess when the test ends and then process the results to estimate the significance. If they do not have the statistical tool to convert a result to confidence bounds then they can use their common sense that if X was winning after 4 hours and still winning by a similar margin after 8 hours, and the number of games is large, that the result is likely significant.
We use this type of procedure all the time. It saves time and allows us to accelerate testing from good advance indications. It is a valuable and simple method.
Jeff Rollason - August 2021
