Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
AI Factory has a comprehensive testbed toolkit that coaxes the AI developer to try stuff and to provide measures for assessing results. It supports parallel testing of multiple AI tweaks providing feedback that informs you what switches work and which switch combinations to try. This is detailed in Adding New Muscle to Our AI Testing and Unwelcome Testing Realities. Without this system it would have been almost impossible to make effective progress with our Spades app. The analysis not only shows what works but also shows you what to try next.
However there are few free lunches and even primed with the powerful armoury above there are pitfalls in testing that are there to mislead you and make life difficult. This article takes a look at one such issue.
Background
The premise of the testing regime is that it allows multiple test results to be cross-referenced and from this you can deduce which parameters are beneficial or not. It also (very importantly) allows testing to detect that A+B is good where A or B alone are weaker. The testing builds a library of testing version test results so that each combination of parameters tested can be compared with a wide variety of other switch combinations, some of which may be old and known to be inferior. This allows a new version to not only prove stronger against the previous best but also against significantly inferior versions. Thereby avoiding the trap of testing P1, P2, P3, P4 as advancing versions where you test P2>P1, P3>P2 and P4>P3, but that on re-test you find P1>P4. By testing against a wide variety of strengths you get a proof of performance against a variety of opponents. I have seen the above paradox happen when the much later version of AI (by one year) was found to lose against the previous year's version.

However there is more.
False Winners
If you run many cross-referenced tests, and the margins of advantage are relatively narrow, then the top version may partly attribute its good position to some added "luck". Taking the extreme case where all versions have identical effective strength then the result would ideally be a massive draw. However that will not happen because of some random luck. This is not so much the luck of just a random dice throw but the luck of a game steered towards a particular play path that might lead a weaker program to beat a stronger one. A weaker version may be able to stumble into exploiting a rare weakness exposed by the stronger opponent.
This may not sound like an issue, but it likely will be. The problem is that having established such a version that now comes out on top, further adding new test parameters can disproportionally fail to displace the top version. The reason is that adding an otherwise beneficial parameter, shifts the game away from the lucky exploit and the new parameter fails.
I confess a struggled a bit to find a good visual metaphor to illustrate this, starting with a number of 3D charts, but resolved down to a simple 2D plot. The reality is that any lucky exploit is the conjunction of maybe many parameters that line up planetary-style wise to deliver access to the path to the exploit. Net, any change to the program evaluation may well kick it off this exploit and deliver a loss rather than a win, even though the change should be stronger. The plot below reduces this to a one-dimensional shift rather than an N-dimensional one (where N is the number of parameters), so it is a somewhat imperfect metaphor, but I hope the idea gets across.
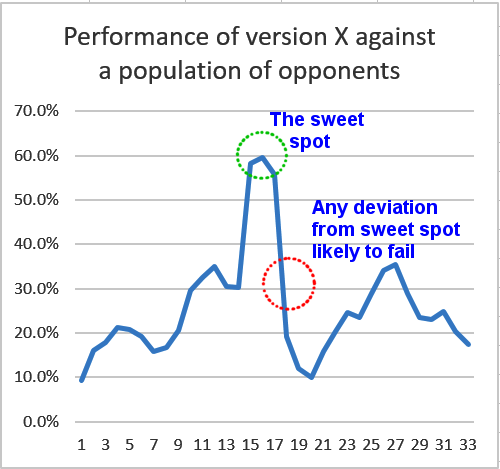
The Consequence
The impact of this is that thereafter you just cannot make progress when adding ostensibly good changes. The version gets kicked off its exploit and does not do so well. And so it becomes a barrier to progress, unless you find some significant new change whose advantage is enough to overcome the negative drag of this loss of exploit. If you are making relatively rare or limited improvements you may find that you are locked into a long period of no progress.
Solutions
At this point I should roll-off a list of easy solutions, but these are not so easy to find. The procedures below comment on ways of addressing the issue. Note that the issue may resolve down to a single exploit in one test or some more subtle exploit that impacts many games. An idea that conveys this would be to imagine early development of a chess program, where all versions under test mess-up king defence on castling. One version might find it is avoiding castling, and finding it wins. Clearly spurning castling is a bad idea, but within the test world avoiding this "good" move yields an apparent benefit.
| 1. | Weed out the exploits | |
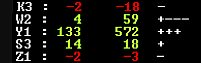
| A solution might be to use the comprehensive analysis in the testbed (see the full table in a previous article) to identify parameters that generally makes the program weaker but that paradoxically in one test make it stronger. In the table below parameter W2 made it weaker 3 times, but on one occasion made the program stronger and by enough to negate the weakening shown in 3 other tests. It therefore looks like an outlier. | ||
|
||
| So, we could check for tests that delivered results that bucked the trend. The tables allow these to be identified. However this is an uneasy solution. When finalising results then the scatter of tests, as driven by the test output, these tend to need to narrow down to a limited block of all-play-all to get an accurate test result. Editing out individual tests that buck the trend conflicts with this and is anyway an uneasy policy. It is reminiscent of cherry-picking scientific papers that deliver the result you want. | ||
| Maybe there is some traction in adopting the idea, but our jury is out on this one. | ||
| 2. | Wait for some single big improvement | |
| This is maybe like waiting for Godot, but if you can find a single substantial change it may be enough to bury the exploit. Once you find it, you will find that all other parameters under test will also need re-test against this new version as it will have changed the play landscape. This is where the existing test framework is so helpful as it allows the tester to keep many parameters in active parallel testing. The idea of keeping a cache of parameters to test in play at the same time proved vital for making our Shogi program Shotest stronger. | ||
| However if no strong new parameter manifests, then you are stuck. | ||
| 3. | Compounding new test parameters | |
| The idea here is that any single improvement may always be tripped up by this exploit hurdle, so rather than reject these one-by-one, try them in various combinations, adding new ones as you go. | ||
| In this case you wait until a combination of incremental improvements is enough to overcome the exploit. The impact can be dramatic as all other parameters that played second best to the other winning parameter can now base advancement from a new position. The original version that was winning may depend on a single parameter that was crucial for the exploit, but that now may be exposed as a weakening. | ||
| This solution is basically the same as "2" above, but premised on a block of parameters. | ||
|
||
| 4. | Analyse and cure the exploit | |
| This sounds like an obvious good solution, but sadly the exploit may be undetectable. It may be exposed by a skew in results from many thousands of games/hands, but you cannot easily detect in which games the exploit manifests. The only path to detecting it is likely to be the analysis of beta tester reports, which may expose the flaw causing it. |

Conclusion
The testbed architecture we have gives the programmer access to a very flexible testing environment. The developer has a good volume of feedback to analyse results. It has proved vital for moving our programs forward. However this broad access exposes that the testing landscape characteristics can be very complex with many non-obvious attributes. Each time the framework is expanded it exposes more candidate properties that may not have been obvious to anticipate. This microcosm AI testing environment may have many more such properties to come that we need to understand in order to successfully fully exploit it.
Here our Spades progress was stalled a while as we had failed to appreciate what was happening. This is one unfortunate aspect of AI development: that it is possible to work very hard but apparently achieve nothing. However we have breached our recent defective exploit and our Spades program is now looking strong.
Jeff Rollason - September 2020
