Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
This article arises from recent work with the card-playing Spades app, where modification testing was starting to mire as I tested multiple versions and the time spent choosing tests became overwhelming inefficient.
To solve this actually required taking another slice from the development of our Shogi-playing program "Shotest", which excelled in the World Championship in Japan. It all came together and work was thereafter both better and much faster.
In the previous article A Rating System for Developers we detailed the RATING program, which provided an ELO-type of system that is actually more sensitive than ELO in extracting performance information. This was also referenced in Lessons from the Road - Championship level AI development, which showed how it was exploited in conjunction with a program that directly read and analysed source files to extract option switches to provide an automated schedule to direct version testing.
Given our endorsement of this system, which was instrumental to taking us to world #3 (and nearly #1) in the World Computer Shogi Championship in Japan, you might question why this was not fully adopted in all our work?
The reason was that this system depended on option switches being embedded in source files, which although it worked, was a little inflexible as any one version of the program could only test one set of switches. If you wanted another test, you needed a new version of the program.
The following shows how this was bridged.
The Game Engine Being Tested
If you are testing a small number of options then block testing of versions can still be managed manually quite well. As per most of our game engines if the number of options under test is greater, then the generic round-robin all-play-all generic tournament tester (see Statistical Minefields with Version Testing) provided a means of setting up block tournaments where switchable features could be tested against multiple opponents.
With our Spades app, our round-robin tournament tester was not available as it was geared for 2 player games and Spades is 4 player, which was not supported. This should invite the question "Why not?". The answer is that for performance testing the classic Spades game, which is a race to a target score, is an insensitive means of assessing strength, as the result is binary. If version A beats version B then it does not distinguish between a 500 to 490 win over 500 to 50 win. Given the time taken to run tests our solution is to set the point limit very high, so that a game result might be 100,000 to 89,000 points, allowing every hand points win to have a direct impact on the assessment.
Given this, the testing framework could not have the tournament tester, which depended on "complete games" won or lost. Given simple option work this work was still manageable with manual control, but Spades was going through a major upgrade, so many features were being tested.
The Mire
The new Spades needed multiple modifications to be tested in parallel. How well each of these worked could not be assessed as independent entities but instead each modification might work better with some other modification.
This started "brightly" but soon I was finding that I was working hard figuring out which test to try next. This required cross-checking and comparing results to figure which test needed to be done next.

The final defect in this was that each result is not perfect. Test results may be outliers and treating them as good results will easily distort the progression for testing.
As the number of items to test increased I gradually found I was grinding to a halt. Something had to give.
Re-introducing the RATING Program with New Support
I knew that what I needed was the automated system I had with Shotest and I needed to pull my finger out to make it happen.
The RATING program was driven by names assigned to versions. With Shotest this management of names against options needed a separate program that mapped version names against options read from source files. I did not have options settings embedded in the source files so I needed a new approach. The version names needed to be replaced by names that embedded the option information. If this was done manually then this would be a great deal of work and invite errors. I needed the Spades testbed to directly manage this for me.
The solution was that when a set of options were being tested that they displayed a name which reflected which options were in use. For example:
S3_SS3_B7_E2_K2_W1
Here "S" is one option and the "3" is a sub-switch. "B" is another with sub switch "7"
S3_____B7_E2_K2_W1
In this second example the option ""SS" has been removed completely, but rather than collapse the name in length it is better to fill with blank space. This makes it easier to compare versions and see which options have been removed from the test. It tabulates better, particularly if the versions are sorted.
Plugging this into the RATING program
Now all I needed to do was to create a text file for input to RATING with the test results. This looked like this fragment:
SS5_B7_E2_K3_W3_P6_A7_X1 8.94 SS5_B7_E2_K3_W3_P6_A7_X1____H2 8.51 ; gamer 0TA SS5_B7_E2_K3_W3_P6_A7_X1 8.99 SS5_B7_E2_K3_W3_P6_A7____Y2 9.68 ; main PC 0TB SS5_B7_E2_K3_W3_P6_A7_X1 9.41 SS5_B7_E2_K3_W3_P6_A5 9.13 ; PC2 0TA SS5_B7_E2_K3_W3_P6_A7_X1 10.68 B7_K3 8.82 ; PC3 0TB SS5_B7_E2_K3_W3_P6_A7_X1 10.03 K3 7.82
The results input to this were massaged as the points totals could be quite close, say 100,000 to 98,000, so these were adjusted to remove the first "N" points from each total and then scale to give a number in the range 5->10 or thereabouts.
Note that the line above contains comments to identify the version and which PC was being used. This was necessary as I had 6 PCs running these tests and still needed to manage which PC was running. Each PC had 4 cores so was running 4 tests. That is 24 possible tests running at once and so I needed something to keep track of which test was where.
To add clarity the test input file could be sorted from time to time so that versions with options in common could be grouped together. This makes it easy to check what versions have not been tested.
The rating source file was input into the RATING program and the output was in the following type of output.
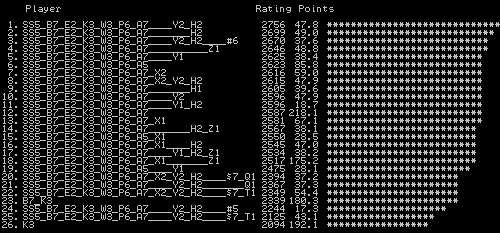
This output is collapsed a little with also only 26 entries instead of the 50 or so in the target file, but the essential elements are there. Key in this is the points column, which gives the total number of points accumulated for each version tested. From this we could see which version might be under-tested. From above you can see that the 3rd rated version has less points than #1, #2 and #4, so this would invite extra tests to see if the rating held.
This still required manual operation and manual choices, but the table above acts as an immediate guide to which options were working and in what combination.
Looking at the output above you can see that options Z1 and H2 individually both do well, but when combined the performance does rather badly. This emphasises the point that options do not just have merit on their own but behave differently in combination.
Conclusion
This may look a bit like admin, but actually powerfully drove the development of Spades much faster and avoided many dead ends. It also handled outlier results, which were no longer assessed on their own but were simply smoothed out by combination with other results.

The net effect was that the key attributes of the options tested were quick to discover and each test run had a clear purpose to clarify results. Previously, in practice, testing was at a dead end as I was unable to see past the mountain of information I had to make a clear choice of how to move forward.
This was a comforting system as the effort to assess results was greatly reduced so that tests could be easily run around the clock, without delays while I stared at the tables figuring out what comes next. The more focussed approach quickly discovered spikes in increased performance around which to test.
The follow-on simplified this to simple program versions, which allowed me to construct something like the all-play-all that the testbed tournament tester provided. This appeared once the range of options was diminished and allowed these to be proven against a variety of opponents.
The end product was the single greatest jump in Spades play performance the product had ever seen.
Jeff Rollason - October 2016
