Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
One of the more interesting recent projects at AI Factory is our new Texas Hold'em Poker engine. This is the most complex of the imperfect information games we have tackled and offered a good opportunity to make use of computer learning. This article outlines our approach and the problems we encountered.
Texas Hold'em - arguably the world's most popular game
There are more known card games and variants than board games, by a very large margin, and maybe even more variants of Poker than board games, and among these, Texas Hold'em is the most popular. To a newcomer the rules and gameplay might seem relatively simple compared to games such as Chess, however it is a complex game with many hidden depths.
Automated Learning
Computer assisted learning has been a very successful technique in the last few years in AI, allowing the creation of the world's strongest Backgammon program, which used a learning neural net. Closer to our work, is the Shogi program Bonanza (Japanese Chess), which was created by someone who had limited Shogi knowledge and who based evaluation simply on crediting on the value of each possible combination of pairs of pieces on all combinations of squares on the 9x9 board. This gives some 1,000,000 possible combinations, each of which has an associated value. Bonanza learnt these values by comparing the net evaluation with known grandmaster games and making tiny adjustments to each term to bring the grandmasters chosen move nearer the top of the list. This was endlessly repeated, with terms being adjusted and counter adjusted as they gradually settled on near optimum values compared to the grandmaster dataset. This successful learning technique allowed Bonanza to win the world championship on its first attempt!
Poker Evaluation
Poker is rather different to Shogi. Most notably it is a game of imperfect information, where the evaluation cannot know the total real game state (it cannot see what cards the opponents have). Taking a simplified overview, there are two primary aspects of Poker play:
The first of these can be addressed on a simplistic level by just assessing the chance of winning a hand, assuming everyone does not fold and assuming random cards. This can be resolved using a basic Monte-Carlo search method where you conduct a large number of trials with randomised cards and simply count up the number of times you win. It is somewhat easier than trying to conduct probability calculations for each type of possible winning combination, which would be extremely complex, given the number of possible ways of winning and then having to compare the chance of each player gaining each combination.
Of course a pure randomised projection of cards is a somewhat incomplete view of the game outcome, as it takes no information from the progression of the game, which is clearly an inadequate basis for real game play. However it is a starting point.
Hidden complexities in win probability
Human players do not do Monte Carlo projections but instead have to depend on probability guidelines. If you look this up on the web or any Poker guide, they will offer rule-of-thumb guides when you should bid or fold. For example in the first round (Pre-Flop) a pair of 3's are playable when the player is a later bidder, but you may need a pair of 7's or better earlier in the hand.
However these guidelines tend to be rather one-dimensional and actually the viability of different card combinations can be more complex than expected. For example how would you assess a 7 hearts + 9 hearts compared to having an Ace hearts + Queen Spades? An Ace + Queen is a good place to start for making strong pairs. The 7+9 looks a little weak, but might make a flush. However (perhaps surprisingly) the other factor is the expected number of players in the showdown. For example in this case above, with 6 players, the raw random probabilities are as follows:
18.84% 7H 9H Predicted Winner 6 players
WinL Win= Lose= LoseH %Wins %Losses
ERankStraightFlush = 360 0.1% 99% 0% 0% 0% 0% 0%
ERankFourOfAKind = 299 0.1% 99% 0% 0% 0% 0% 0%
ERankFullHouse = 5325 2.2% 86% 5% 6% 1% 10% 0%
ERankFlush = 15326 6.4% 73% 0% 0% 13% 25% 1%
ERankStraight = 17529 7.3% 58% 7% 6% 24% 25% 2%
ERankThreeOfAKind = 10232 4.3% 43% 6% 7% 40% 11% 2%
ERankTwoPair = 52646 21.9% 8% 10% 24% 54% 22% 22%
ERankPair = 98853 41.2% 0% 1% 7% 90% 3% 50%
ERankHighCard = 39430 16.4% 0% 0% 0% 98% 0% 20%
18.17% AH QS Predicted Winner 6 players
WinL Win= Lose= LoseH %Wins %Losses
ERankStraightFlush = 25 0.0% 100% 0% 0% 0% 0% 0%
ERankFourOfAKind = 310 0.1% 100% 0% 0% 0% 0% 0%
ERankFullHouse = 5249 2.2% 85% 10% 2% 0% 11% 0%
ERankFlush = 4757 2.0% 74% 0% 0% 13% 8% 0%
ERankStraight = 8815 3.7% 57% 13% 2% 24% 14% 1%
ERankThreeOfAKind = 10648 4.4% 42% 11% 2% 42% 13% 2%
ERankTwoPair = 54242 22.6% 8% 25% 8% 56% 42% 18%
ERankPair =109428 45.6% 0% 3% 4% 90% 10% 53%
ERankHighCard = 46526 19.4% 0% 0% 0% 99% 0% 23%
WinL is "win against lower hand", Win= "win against hand of equal ranking (i.e. 55 beats 44 etc)"
From these randomised trials a 7 hearts + 9 hearts has a better chance than Ace hearts + Queen spades. However if the showdown only has 2 players, the advantage for winning changes:
51.91% 7H 9H Predicted Winner 2 players
WinL Win= Lose= LoseH %Wins %Losses
ERankStraightFlush = 374 0.2% 100% 0% 0% 0% 0% 0%
ERankFourOfAKind = 311 0.1% 100% 0% 0% 0% 0% 0%
ERankFullHouse = 5324 2.2% 97% 1% 1% 0% 4% 0%
ERankFlush = 15549 6.5% 93% 0% 0% 2% 11% 0%
ERankStraight = 17471 7.3% 90% 2% 1% 5% 12% 1%
ERankThreeOfAKind = 10248 4.3% 84% 2% 2% 10% 7% 1%
ERankTwoPair = 52584 21.9% 61% 9% 13% 15% 29% 13%
ERankPair = 98752 41.1% 17% 21% 22% 38% 31% 52%
ERankHighCard = 39387 16.4% 0% 7% 10% 82% 2% 31%
54.03% AH QS Predicted Winner 2 players
WinL Win= Lose= LoseH %Wins %Losses
ERankStraightFlush = 31 0.0% 100% 0% 0% 0% 0% 0%
ERankFourOfAKind = 313 0.1% 99% 0% 0% 0% 0% 0%
ERankFullHouse = 5375 2.2% 97% 2% 0% 0% 4% 0%
ERankFlush = 4824 2.0% 93% 0% 0% 2% 3% 0%
ERankStraight = 8744 3.6% 89% 3% 0% 5% 6% 0%
ERankThreeOfAKind = 10589 4.4% 84% 3% 0% 10% 7% 1%
ERankTwoPair = 54514 22.7% 60% 19% 4% 15% 33% 9%
ERankPair =108506 45.2% 17% 30% 13% 38% 39% 51%
ERankHighCard = 47104 19.6% 0% 13% 3% 82% 4% 36%
From this you can see that with just 2 players, Ace Hearts + Queen Spades is now clearly better. This may look inexplicable until you examine where the wins are obtained. In the 6 player case AH + QS is hardly ever winning with a simple pair (10%), as with 6 players the chance of a stronger hand winning is much higher. About 33% of the wins are dependent on a Straight or higher. However with just 2 players a simple pair is much more likely to be the winning hand, accounting for 39% of all wins with a Straight or higher only providing 13%.
This gets somewhat more complex once "The Flop" has been played as general guidelines are less helpful as the probability calculations get more difficult. Happily Monte Carlo has no problems with this and any complex combination of hand and table cards is just as easy to estimate.
Preparing for Learning
Computer learning has a seductive appeal as it maybe suggests that the engineer can get away with a minimal evaluation framework and leave it to automated learning to find the desired evaluation. However this falls down. As many AI engineers will attest most computer learning sessions actually yield nothing. The AI engineer is relieved of some important aspects of tuning but still has to create the viable core. Assessing what is needed:
Firstly computer learning depends first on an evaluation framework that is actually capable of expressing the desired winning evaluation. If no combination of terms results in good play, then automated learning will not find it.
Secondly you need to have a framework that is constructed so that it is amenable for learning. If the framework is oversensitive to the exact solution and cannot allow the expression of similar sub-optimal solutions, then the learning will have a hard time finding its way to getting the right result.
Finally "learning" can take many possible forms. As described in the earlier Evaluation by Hill-climbing: Getting the right move by solving micro-problems the natural way to reach the correct solution is to incrementally hill-climb to the desired summit. This is the core idea behind most AI learning.
Creating a Game Engine Core before Learning
To get started it is necessary to create the evaluation framework. This is dark art that requires both inspiration as well as logical analysis. The core to this is assessing the likely return for the required bet. On a simplistic level betting $10 with a 20% chance of winning $50 is the break-even point. If the winnings were $60, then this looks a good bet, whereas $40 might not. Of course we do not have this as a nice clear exact probability estimate as the probability depends on other game information other than just raw probability. If you are in the PreFlop and three players before you have raised, then this raw probability estimate is probably somewhat optimistic. If you are the first to bet and there are 8 players to follow you, you have to realise that it is quite likely that one or more of these will have had significantly above-average cards and this should skew your assessment.
The method used to put this together was to create a series of linear terms that factored in a number of terms that could impact the player decision. The initial set had 22 such terms, each expressing some aspect of play. The values to be learnt were set so that they each ranged between 0 and 100. To allow these to be learnt from, it is desirable that the likely "correct" setting is not heavily skewed to one end. It will not be good if the optimum setting in a range is 0 in the range 0->100, as this implies some other lower setting may be correct.
Adding Explicit inference to the Game Engine
Above I indicated that the Monte Carlo projection did not care about game progression: it only assessed the cards it could see. However this is unnecessarily inadequate. The next essential step is to allow the Monte Carlo projection to skew its choice of dealt cards by reading player responses. If a player calls in the first round, "Pre Flop", and then suddenly raises heavily in the second round, "The Flop", then it is very likely that the player has cards that connect with the 3 cards played to the table. So if the table has AH + JS + 6C, then we can make a series of inferences about the likelihood that the players also has A+J+6 and also cards in sequence. By the same measure, if a player fails to raise or bet in The Flop, it is an indication the table cards probably failed to improve their hand.
The engine makes use of this by making a number of positive and negative inferences, so that an estimation that player X has an Ace means that during projection that they will more likely be dealt an Ace. This method is described in the earlier article Predicting Game States in Imperfect Information Games, which showed this used in the simple game of Gin Rummy.
Ready to Start Learning
Now we have a set of learnable parameters and an engine that may be able to represent a winning evaluation. The next step is to consider how we do this. Plan A might be to simply seed the parameters with initial plausible values and set the program off modifying and testing these to detect in which direction each parameter needs to be adjusted. The hill below represents this assumption. Of course it projects this as a 2-parameter climb, which has a comprehensible 3D visual representation, but actually our hill is not 3 Dimensional but 22 Dimensional.
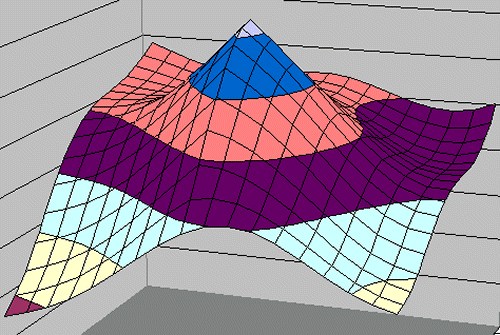
The ideal case: The single hill climb
However this single hill is a somewhat optimistic assumption. A more likely scenario is the following multi-hill situation below. Here there are many possible hills. We need to know if there are multiple hills and a means of avoiding getting stuck on some local sub-optimal maxima:
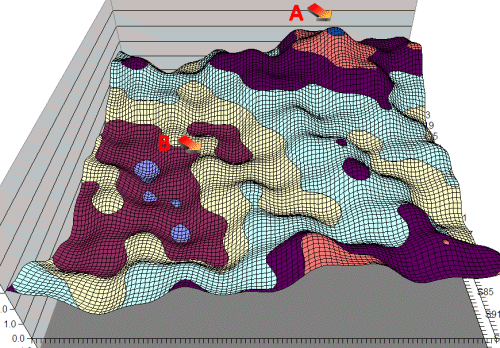
Many hills: We climb "B" but should be on "A"
This situation is not only possible, but regrettably very likely. To take a simple instance of this, it is very easy to have two evaluation terms that complement each other, so that if one increases the other needs to decrease. If you are simply modifying a single term and testing, you will never be able to detect the 2-parameter optimum point. However it is worse than that as we actually have 22 terms, so the possibilities become endless.
Learning Scheme one: Climb all Hills
In the literal sense we cannot exhaustively climb all hills as the possible space to explore is endless. There are vastly more possible parameter combinations than there are atoms in the known universe. The scheme we have used to get started is to randomly try all hills and allow these to compete with each other. This is done by randomly selecting each parameter and then testing for success or fail. If the parameter succeeds then the terms used get a vote or no vote if they fail.
If this is allowed to free run then the rate that good parameters succeed will be low as they will be combined with poor random values of other parameters. The end product has so much "bad value" noise that nothing useful would come of it.
However, in our scheme, the chance that a parameter will be chosen will depend on whether it has been previously successful or not. The graph below shows an example of this.
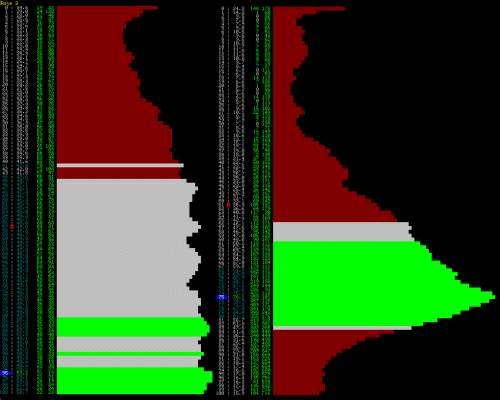
Early multi-hills compete to resolve to a single winning hill
Here, looking at the left graph, early results showed a couple of limited peaks near the upper range at 83 and 97 of the series and a middling performance around 45 to 80. The range below 45 significantly tailing off with a minor sub-peak around 0.
As this was allowed to free run, each tested parameter gradually increases the chance that it will be tested with other more successful setting of other parameters, as these get votes and therefore become more eligible for re-selection. This changes the dynamic and the peaks drift and eventually one peak starts to win out as the other successively gets less votes. On the right hand of the graph above, a new peak has appeared in the "moderate" region, around the value 76 and the previous peaks at 83 and 97 have faded out.
This looks pretty promising, and allowed the engine to obtain some plausible settings that seem to hit a plausible maxima from this population of maximas. This offers no guarantees that we have actually come close to finding the real maxima in this search space, but it is very likely much better than most maximas.
Progressing to Fine Tuning: Learning Scheme two
The scheme above allows you to find a good region for a plausible good maxima, but is actually poorly tuned as most test opponents only have approximately good parameters. To get good tuning then requires new methods. The following were tried:
Scheme (1) above is painfully slow and requires the selection of the parameters to test. Each varied parameter is tested with all other parameters preset to their current optimum best. These can be all tested in sequence, but then usually it only proved possible to update the results one at a time before re-testing. Changing several parameters at once usually resulted in inferior play.
Scheme (2) above is not that fast but actually works quite well. The program sets a series of parameter tweaks, perhaps changing only about half the parameters, randomly selected, and then auto-tests these. If results start to look bad it rejects them and tries a new set until it finds a set that stays ahead. This is run on say 16 processors, each looking for some new better set and from these one or more good sets are used as a base for further testing.
When learning, the program uses a 10-player game, where 5 of the players are recent "best" players, one is an aggressive version of the current base set and one a timid version of the base set. A further 3 players are randomised learning players, using one or two learning methods.
Conclusion
Although the description above portrays what appears to be a uniform successful progression, it actually required many inevitable re-starts. Each time some term was added, or a bug found, the learning more-or-less had to re-start as the dynamic had changed. This was sometimes pre-skewed so that the learning started with a diluted version of what it had already learnt, on the basis that the new maxima may not be that far off the old one. This required tweaking and tuning. It also involved periods where the engine seem to lose the capacity to learn at all and this needed the learning mechanism to be re-tweaked so that it could progress.
Early versions, with important areas of knowledge missing, quickly learned to play very badly, if they could get away with it. The early Poker was unable to respond to strong bluffing so each learning player found that excessive bluffing was very successful, so bluffed pretty well all the time.
Note that this learning universe is for matches that cannot be observed, as they progress at very high speed. 20 hands will be played in under one second. Therefore the evolving players are not easily observed. It then required manual testing of the new learned player to see what they do. As was often the case they deviated from known best play, so this exposed some further weakness in evaluation.
The original 22 terms quickly became 45 terms as new knowledge was added. These include terms that control bluffing. This closed progression was also tested against the well known Poker Academy program, which provided useful insights into its play as the program's choice could be compared with the Poker Academy's recommendation. Initially the goal was to mirror Poker Academy's advice but increasingly our program deviated from this and usually scored higher than the Poker Academy Bots, mostly coming 1st or 2nd among 10 players.
The long-term conclusion of this is some time away as it is still a young program. However it currently seems stronger than the widely regarded Poker Academy, and can play very quickly, so is already on a good track. This engine is already being implemented in a commercial product.
Jeff Rollason and Daniel Orme - July 2009
